Google I/O这周各种刷屏,媒体的报道覆盖了 Keynote 的边边角角,速度之快,总结之准确,配图之清晰,仿佛身临其境。看来看去,今日头条最快,机器之心引证最深,有几个个人作者耐心看了相关 Session 的视频也做了一些 PPT 总结。总觉得少了点什么。

媒体只说性能提升8倍,知道和谁比的么?(这图看腻了吧)
既然笔者也在现场学习了几天,就分享一下之前媒体上没有的内容吧。先揭秘:媒体们普遍引用的 Keynote 图片:性能提升8倍,指的是 TPUv3 Pod (100+ Petaflops)对比 TPUv2 Pod(11 Petaflops) 的性能提升。证据如下图:

本文图片不做梯形修正和白平衡修正,以区别于 YouTube视频截图
Google I/O 就是一场以A.I为核心的春晚
概括来说,Google 这次发布的几个新品都是围绕“人工智能(A.I)”展开的,从机器学习创造的音乐开场,到Google Assistant震惊四座的“代打电话”,再到Google Duplex, Android P为APP开发者降低 A.I 门槛的机器学习套件(ML Kit), 子公司Waymo出来讲无人驾驶 Blablabla…
相比去年,Google 从只讲机器学习技术的 Geek,变成了会讲故事的老司机。毕竟光说自己酒精提纯工艺多好没人感兴趣,酿成酒端出来才有食客。
幕后功臣登场:TPU 3.0和基于它的 TPUv3 Pod(你可以理解为 一个固定的TPU 集群,大盒子)。但是 Google 表示我就是在这个会议上炫耀一下,不给你用。但是今年晚些时候会在 Google Cloud(下称 GCP) 上开放给大家租用基于 TPU 2.0的 TPUv2 Pod,性能自然是没话说(价格目测也是飘到了天边)。
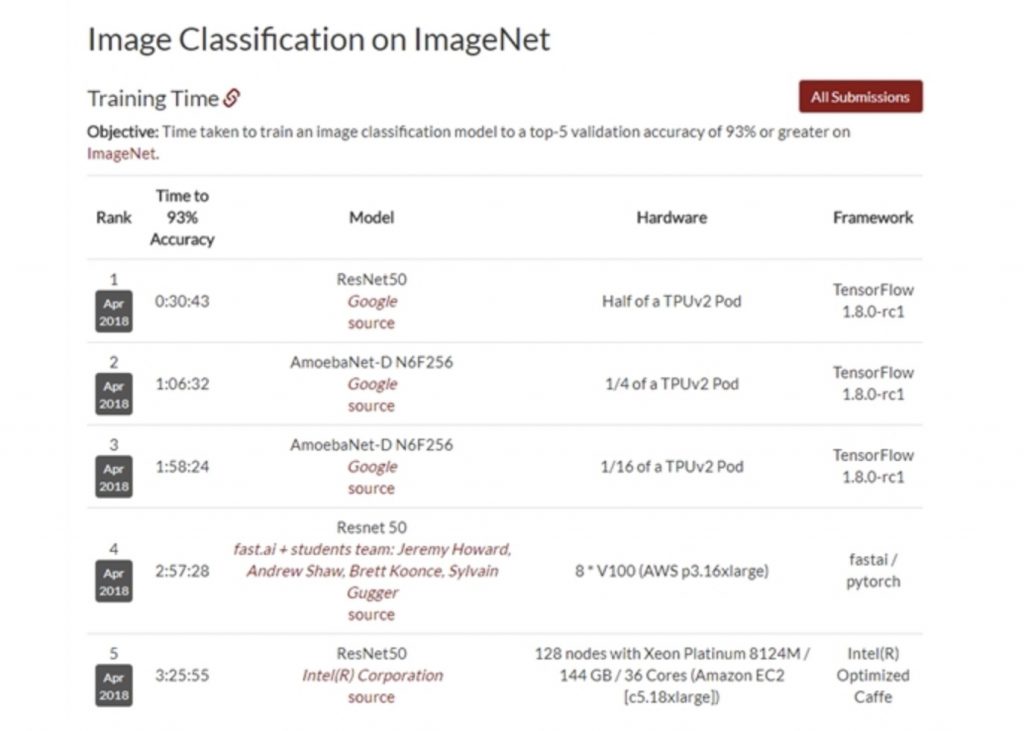
前三名被TPUv2 Pod包揽, 就算是第一名也只用了半个 TPUv2 Pod‘(斯坦福大学最新4月份DAWNBenchmark榜单的成绩,比的是图像识别准确度达到93%的时候,谁用的时间减少)
Google I/O 的各个 Session 课程里除了介绍了一些技术细节和经验外,更多的是给自己的 GCP 卖广告——告诉你用 TPU 训练多省时间多省钱,效果多好,一大堆例子如图(图片们呐喊着快来用我吧):

花篇幅讲案例不忘放价格,做得一手好广告
TPU 3.0 和 TPUv3 Pod
TPU 是什么?
张量处理器(英语:Tensor Processing Unit,缩写:TPU)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。
与GPU相比,TPU采用低精度(8位)计算,以降低每步操作使用的晶体管数量,这对于深度学习的准确度来说影响很小,却可以大幅降低功耗、加快运算速度。同时,TPU使用了脉动阵列的设计,用来优化矩阵乘法与卷积运算,减少I/O操作。利用自身更大的片上内存,来减少对DRAM的访问,从而更大程度地提升性能。——摘自Wikipedia,删了点废话
TensorFlow 及Cloud TPUs的产品经理 Zak Stone 在Google I/O 的课程里详细讲解了上述 Wikipedia 说的几个词:包括为什么自定义了浮点标准,也谈到了上文里晦涩的脉冲阵列设计(Systolic Array)
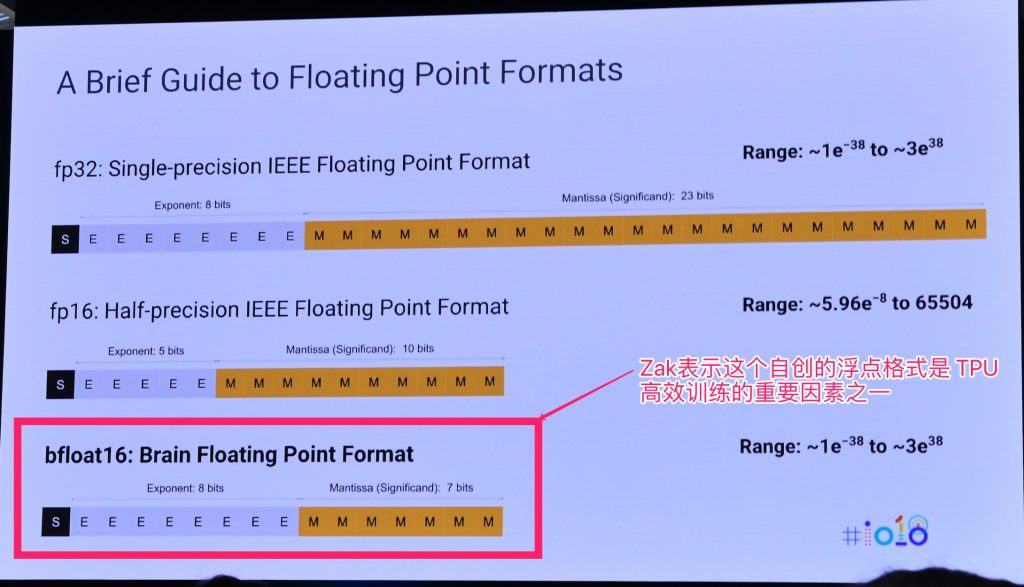
TPU第二代开始自定义的 bfloat16浮点格式(非 IEEE标准)

这是 TPUv2架构图的一部分,Systolic Array是 Matrix 计算单元的一部分,实际上这部分主要就是为了做神经网络里的矩阵乘法和卷积进行加速
Google 的这三代 TPU 不太好直接比较(主要是 TPU 3.0没有公开数据),每一代架构甚至功能都有变化,可以这样理解:
- TPU v1 计算力 92 Teraflops,8Gb 内存,34GB/s 内存带宽,只能做推理(其实这是个 PCI-E 的加速卡,上面插了两条2133Mhz DDR3的内存)——它的光荣成绩是打败了李世石(4 个TPU推演,GPU 训练的 AlphaGo Lee 版本)
- TPU v2 计算力 45Teraflops,16Gb 内存,600GB/s内存带宽(和显卡学习集成的 HBM),看起来单 TPU计算力慢了不少? 既可以做训练,也能够推理——它的光荣成绩是打败了柯洁和一大堆其他人类高手(4个 TPU 推演,TPUv2 Pod训练的 AlphaGo Master版本,之后的 AlphaGo Zero 也诞生在这上面)
- TPU v3 ???? 既可以做训练,也能够推理(它应该和这次突飞猛进的 Google Assistant 以及 Waymo 的无人车有重大关系)

TPU v3的功耗肯定是蹭蹭蹭的涨,水冷作证
石头哥(Zak Stone)比较鸡贼的放了下面这张 PPT,用一个 TPU v2节点(4个 TPU)来避免尴尬:

最下面的是TPUv2 Pod,今年下半年会在 GCP 上提供租用——其实之前的图片里已经有跑分了(AlphaGo Zero 就是在这上面训练出来的哦)
虽然Google对于TPU 3.0非常意外的没有透露细节,倒是透露了很多 TPU v3 Pod 的信息——请回去看看文章开头的配图—— >100 Petaflops的性能巨兽(莫名想到了 Nvidia 的 DGX-2小怪兽)。
是不是没有说 TPU 3.0的什么内容感觉被骗了。 来点独家信息吧:
笔者拦住石头哥问他 TPUv3 Pod 这种怪兽,众多 TPU 节点之间你们怎么通信的?用的标准以太网?还是和 DGX-2一样用InfiniBand? 带宽?延迟?
>>石头哥使劲呼吸了两口:“The only thing I can tell you is that we solved this by ourselves. Each TPU node has enough bandwidth talk to others. ” ——唯一能告诉我的就是Google 自己解决了通信的问题,每个TPU节点间的带宽都足够。
你们TPU Pod用自己的专有的网络?
>“From my understanding, yes.” ——可以这么说
那你们怎么上云?用户都是以太网的协议
>>石头哥解释了一波 Google Cloud会先做好相关的准备,租用 TPU Pod 的用户不会有相关的感受。
TPUv2 Pod开放租用以后,也和 TPU 一样只支持 Google 自己的 TensorFlow 么?
>>Yes.